Getting set up with Docker and the Ontology Development Kit¶
Installation¶
For Windows¶
- Follow the instructions here. Note that you should have Windows 10 Professional installed for this to work. We are not sure Docker Desktop works at all with Windows 10 Home, but we have not tried in a while. If you know what you are doing, you could try to configure Docker toolbox, but we have had many issues with it, and do not recommend it unless absolutely necessary.
- If you are unable to install Docker Desktop on your Windows PC (e.g. no admin rights or prohibited by the IT department of your institution) but you have the ability to use the Windows Hyper-V-Manager (possible w/o admin rights) or another virtualization tool, such as VirtualBox, you could set up a Linux virtual machine (VM) to use ODK. We recommend using Lubuntu, as it won't need much computing resources. Although you cannot install Docker Desktop in such a VM, you can install the Docker Engine, which suffices to proceed with the next step.
- A much more convenient way to use a virtual Linux environment (with admin rights) is via the Windows Linux Subsystem (WSL) in Windows 10 and above. Installing it and the Docker Engine will allow you to use ODK in a Linux shell environment, while working with Protégé, GitHub Desktop and other possibly helpful apps like PyCharm, in your regular Windows GUI environment.
- Once installed, you should be able to open your command line and download the ODK.
- Click on your Windows symbol (usually in bottom left corner of screen), type "cmd" and you should be able to see and open the Command Line tool.
- in the command line type, type
docker pull obolibrary/odkfull. This will download the ODK (will take a few minutes, depending on you internet connection). - Executing something in a Docker container can be "wordy", because the docker container requires quite a few parameters to be run. To make this easier, we prepared a wrapper script here. You can download this file by clicking on
Raw, and then, when the file is open in your browser, CTRL+S to save it. Ideally, you save this file in your project directory, the directory you will be using for your exercises, as it will only allow you to edit files in that very same directory (or one of its sub-directories). - Setting the memory: Typical issues (WSL 1 vs 2)
For Mac/Linux¶
- Install docker: Install Docker following the official instructions.
- Make sure its running properly, for example by typing
docker psin your terminal or command line (CMD). If all is ok, you should be seeing something like:
- Run
docker pull obolibrary/odkfullon your command line to install the ODK. This will take while. - Download an ODK wrapper script. The odk.sh has further instruction on how to best use it.
- Now you are ready to go to a directory containing the odk.sh wrapper script and running
sh odk.sh robot --versionto see whether it works. - The ODK wrapper script is generally useful to have: you can for example enter a ODK container, similar to a virtual machine,
by simply running
sh odk.sh bash(to leave the ODK container again, simply runexitfrom within the container). On Windows, userun.bat bashinstead. However, for many of the ontologies we develop, we already ship an ODK wrapper script in the ontology repo, so we dont need the odk.sh or odk.bat file. That file is usually calledrun.shorrun.batand can be found in your ontology repo in thesrc/ontologydirectory and can be used in the exact same way.
Problems with memory (important)¶
One of the most frequent problems with running the ODK for the first time is failure because of lack of memory. There are two potential causes for out-of-memory errors:
- The application (for example, the ODK release run) needs more memory than assigned to
JAVAinside the ODK docker container. This memory is set as part of the ODK wrapper files, i.e.src/ontology/run.batorsrc/ontology/run.sh, usually withODK_JAVA_OPTS. - The application needs more memory than is assigned to your docker installation. On most systems (apart from a handful fo Windows ones based on WSL), you have to set docker memory in the docker preferences. That happens here is that the Java memory above may be set to something like 10GB, while the maximum docker memory is set to 8GB. If the application needs, say, 9GB to run, you have assigned enough Java memory, but docker does not permit more than 8 to be used.
Out-of-memory errors can take many forms, like a Java OutOfMemory exception,
but more often than not it will appear as something like an Error 137.
Solving memory issues¶
Setting memory limits:¶
There are two places you need to consider to set your memory:
- Your ODK wrapper script (see above), i.e. odk.bat, odk.sh or src/ontology/run.sh (or run.bat) file. You can set the memory in there by adding
robot_java_args: '-Xmx8G'to your src/ontology/cl-odk.yaml file, see for example here. - Set your docker memory. By default, it should be about 10-20% more than your
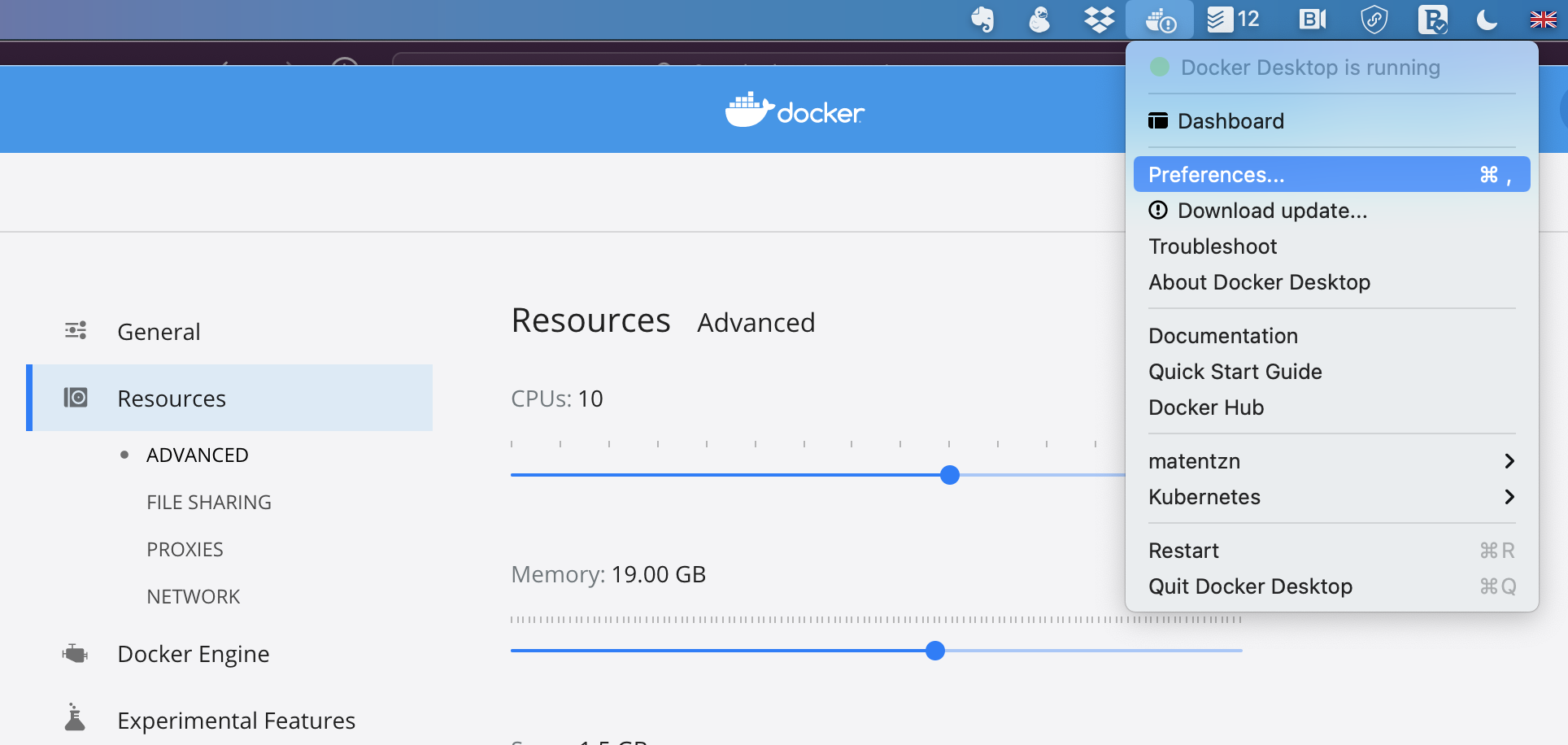
robot_java_argsvariable. You can manage your memory settings by right-clicking on the docker whale in your system bar-->Preferences-->Resources-->Advanced, see picture below.
More intelligent pipeline design¶
If your problem is that you do not have enough memory on your machine, the only solution is to try to engineer the pipelines a bit more intelligently, but even that has limits: large ontologies require a lot of memory to process when using ROBOT. For example, handling ncbitaxon as an import in any meaningful way easily consumes up to 12GB alone. Here are some tricks you may want to contemplate to reduce memory:
robot queryuses an entirely different framework for representing the ontology, which means that whenever you use ROBOT query, for at least a short moment, you will have the entire ontology in memory twice. Sometimes you can optimse memory by seperatingqueryand otherrobotcommands into seperate commands (i.e. not chained in the samerobotcommand).-
The
robot reasoncommand consumes a lot of memory.reduceandmaterialisepotentially even more. Use these only ever in the last possible moment in a pipeline. -
`